
- You can't balance a game by playing it — the matchup space is bigger than you can ever sit through. Let the computer play it tens of thousands of times and read the distribution instead.
- Make one playthrough a pure, seeded function (no global state, no disk writes). Then it's a unit you can call 60,000 times in a loop.
- Chimera (creature breeder): rarity tiers fall straight out of a 20,000-genome sample; 60,000 controlled battles showed Gore won 62% — and a knob sweep proved the damage number wasn't the culprit, the guard-pierce was (~7.5pp on its own).
- King & Dragon (economy game): median knight had 99 gold, but the P95 had 20,604 and the richest 565,216. The mean and median both walked past a tournament exploit. Only the percentiles caught it.
- The whole lesson: the mean lies; balance bugs live in the tail. And you're balancing against your AI, not humans — it's a flashlight, not an oracle.
You cannot balance a game by playing it. I tried. You sit down, you play twenty matches, you get a feeling that one option is too strong, you nerf it, and you've just thrown away your only data point — your own twenty games — to chase a hunch. The combinatorics beat you. A handful of stats, a few abilities, some randomness, and the space of possible matchups is larger than you can ever sit through by hand.
So I stopped playing my games to balance them. I let the computer play them instead — tens of thousands of times — and then I read the results. That's Monte Carlo, and it's the only honest way I've found to answer "is this fair?" with a number instead of a vibe.
This post is the method, with real data from two games I built: Chimera, a creature-genetics breeder, and King & Dragon, a medieval economy game. Both got balanced this way. Both taught me the same lesson, which I'll spoil up front because it's the whole point:
The mean lies. Balance bugs live in the tail.
What Monte Carlo actually means here
Strip away the casino name and it's three steps:
- Simulate a playthrough with randomised inputs — random creatures, random AI strategies, random seeds.
- Repeat it thousands of times and collect the outcomes into a distribution.
- Tune one parameter, re-run, and watch whether the distribution moved toward fair — typically a win rate near 50%.
That's it. No analytic genius required. You're trading math you can't do (the exact probability of a 32-turn game ending a particular way) for math the computer can: count how often it happened.
The one prerequisite that matters: your simulation has to be deterministic from its seed and free of side effects. Same seed in, same result out, nothing mutated on disk. Get that and a single game becomes a pure function you can call sixty thousand times in a loop. Skip it and your "experiment" is just noise you can't reproduce.
Case 1: Chimera — when you can't derive the probability, sample it
Chimera's battles are 1v1, turn-based, and stat-pure: the resolver reads a creature's phenotype and plays out the fight. The important design decision was making resolve_battle(seed, a, b) fully deterministic and persisting nothing. That wasn't for balancing originally — it was so async "ghost" battles replay identically for anti-cheat. But a deterministic, pure battle is also the perfect Monte Carlo unit. Free reuse.
Rarity is already Monte Carlo — and it ships
Before I balanced a single fight, Monte Carlo was running in production for a different job: rarity.
A creature's rarity is the compound probability of every notable trait it expresses — colour, shape, shininess, horns, wings, legendary status. Deriving that by hand means multiplying out dominance, penetrance, epistasis, allele weights, and mutation. It's a nightmare, and it goes stale the moment I add a gene.
So I don't derive it. I sample 20,000 random wild genomes once (fixed seed, so it's reproducible), tally what actually shows up, and score each creature by its percentile against that measured population. The tier is the percentile. It self-calibrates as the gene pool grows.
Here's what 20,000 samples measure:
| Trait | Frequency in 20k wild sample |
|---|---|
| Shiny | 0.66% |
| Horns | 44.6% |
| Wings | 36.8% |
| Legendary "Warden" | ~15.8% |
| Legendary "Prismatic" | ~1 in 2,000 |
| Legendary "Spectre" | 1 in 20,000 (showed up once) |
The rarest creature in that sample had a combined trait probability of about 6 in 10 billion — roughly one in 1.6 billion. I would never have hand-computed that. The sampler just found it.
Drop the percentiles into tiers and you get a clean pyramid, which is exactly the shape a rarity system should have:
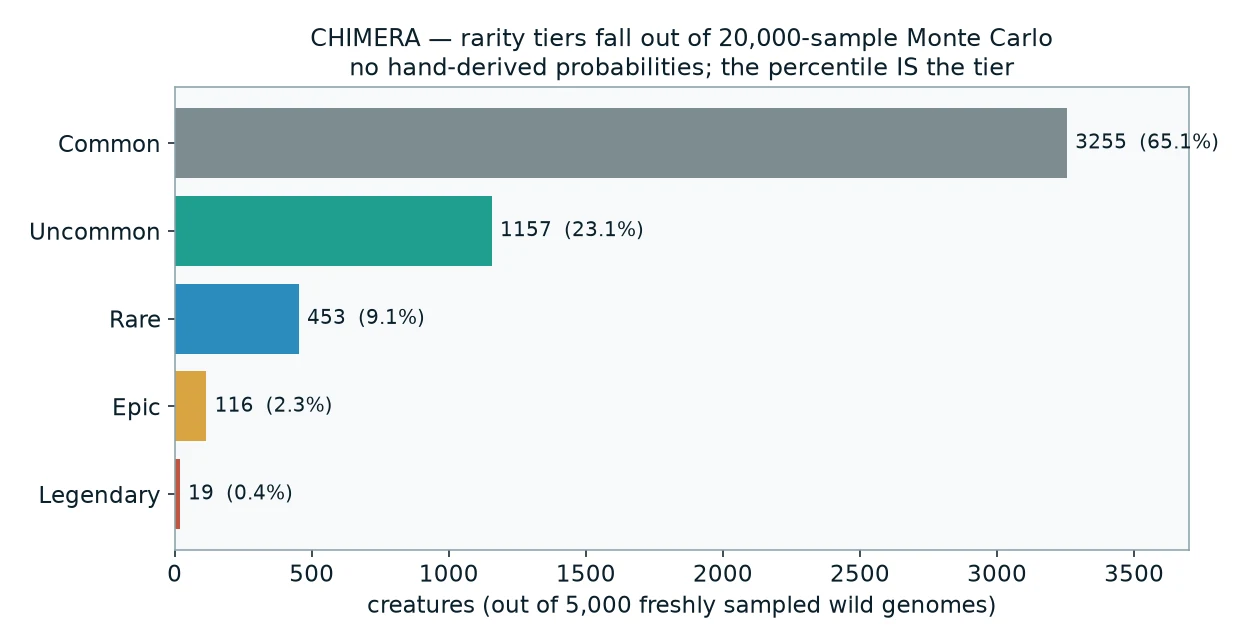
No magic numbers in that chart. Every cutoff fell out of the distribution.
Balancing the combat knobs
Now the actual balancing. Chimera has gene-gated special actions — Gore for horns, Swoop for wings, Venom Spit for venomous creatures — each with a damage multiplier I can set live. The question: are they fair?
Naively you'd pit creatures with the action against creatures without and count wins. But that's confounded — horned creatures might just have better stats. So I sample 60,000 random battles and keep only the matched ones: exactly one side has the action, and both sides are within ±2 of the same total stat budget. That isolates the action's contribution from raw power.
At shipped defaults, here's what 60,000 battles said:
| Action | Multiplier | Controlled win rate |
|---|---|---|
| Gore (horns) | 1.4× | 62.0% |
| Venom Spit | 0.85× | 48.5% |
| Swoop (wings) | 0.8× | 34.5% |
Gore was overpowered, Swoop was a trap, Venom was nearly perfect. Then I swept each multiplier and re-measured to find where each lands fair:
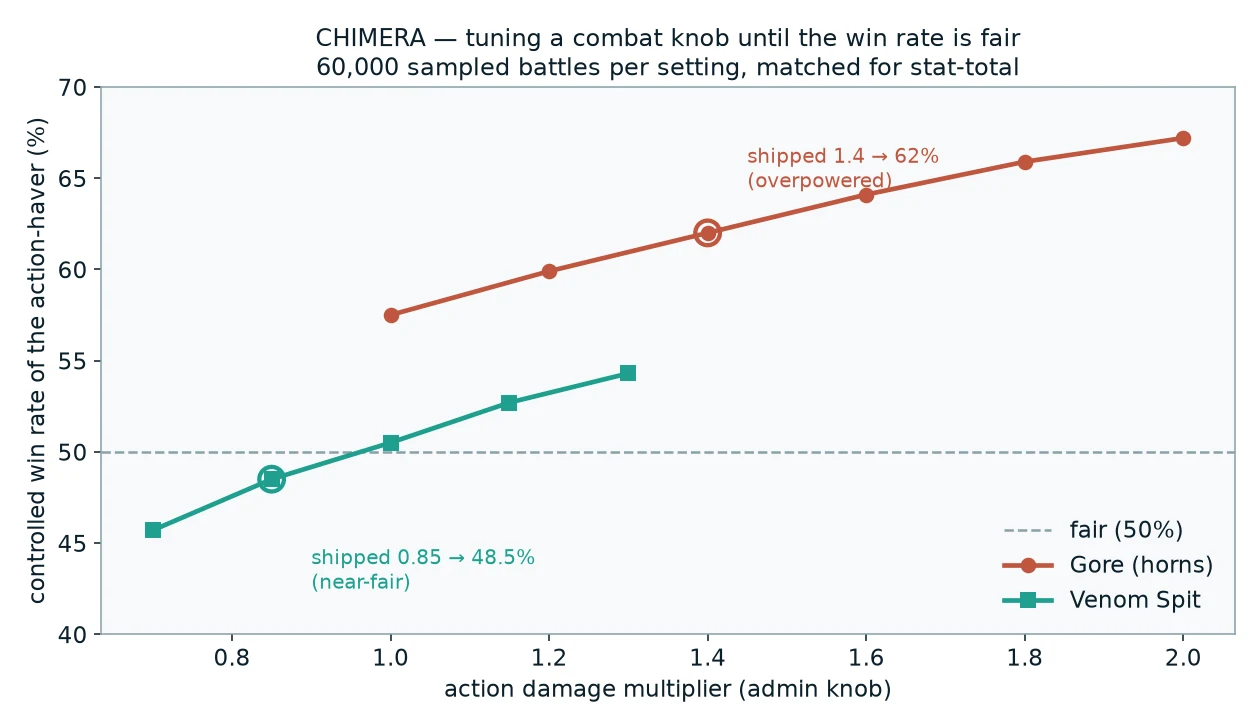
Venom was easy: bump 0.85× to 1.0× and it sits at a dead-even 50.5%. Done.
Gore was the interesting one — and here's where Monte Carlo earned its keep. Look at the left end of that line: even at a multiplier of 1.0×, Gore still wins 57.5%. The damage bonus isn't the problem. Gore also pierces Guard, and that property alone is worth about 7.5 points of win rate, completely independent of the multiplier. I would have nerfed the number, watched it stay broken, and been baffled. The simulation told me the truth: you can't balance Gore with the multiplier alone — you have to weaken the guard-pierce too.
That's the kind of thing intuition cannot quantify and a hundred hand-played matches will not reveal.
Case 2: King & Dragon — the mean lied, loudly
King & Dragon is a different beast and a different scale. It's a medieval economy game: one AI king and 31 NPCs (16 peasants, 8 townsfolk, 4 knights, 2 princes), each running a random strategy — conservative, greedy, generous, bluffer, survivor — across up to 32 turns of tax declarations, dragon tribute, dragon attacks, and revolts. A single Monte Carlo "game" is an entire AI-vs-AI playthrough, not a duel.
The baseline run is 10,000 games at a fixed seed; parameter sweeps run 5,000 games per value. That's how the kingdom win-rate got tuned toward its ~50–60% target — for example, raising NPC income from 200 to 350 gold per turn to land near 50%.
But the best story came from a separate, smaller run: a tournament rebalance, 500 games per variant. Knights could enter tournaments to win gold and weapons. On the surface the economy looked fine — the median knight finished with about 99 gold. Healthy. Boring. Balanced.
Then someone looked at the percentiles.
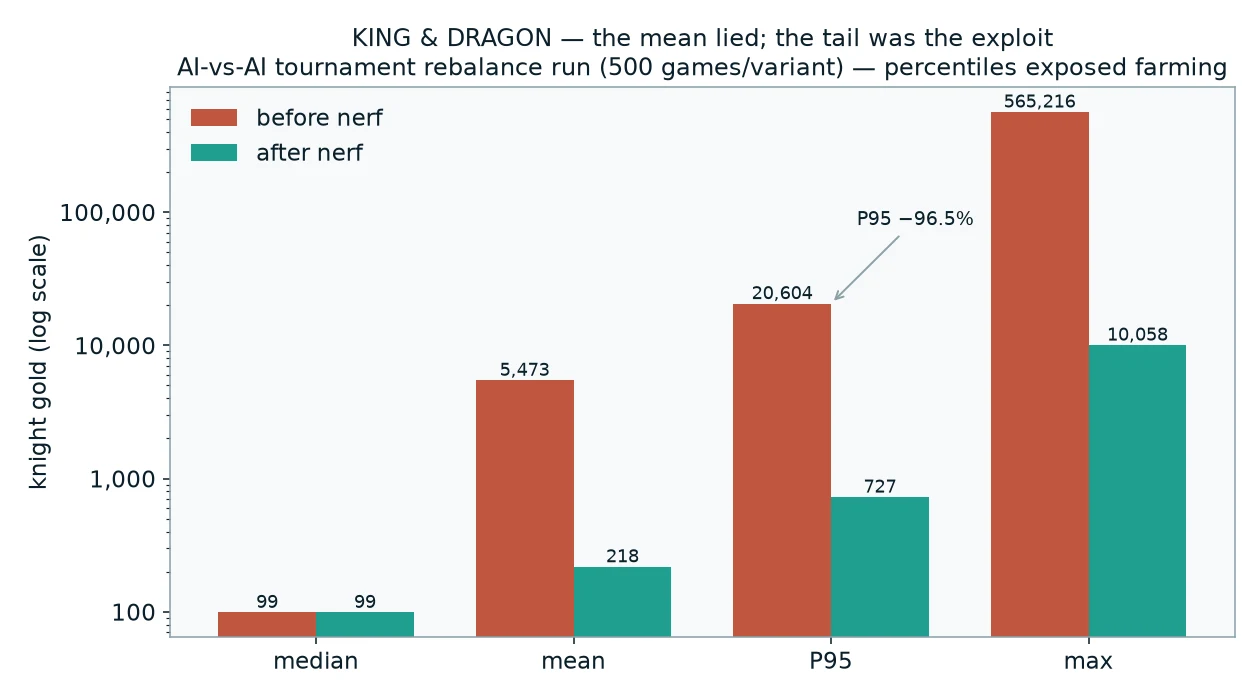
The median knight had 99 gold. The 95th percentile had 20,604. The richest had 565,216 — nearly six thousand times the median. That's a fat tail, and it was an exploit: nothing stopped a knight from farming tournaments forever, so the lucky/persistent ones spiralled into absurd wealth. The mean (5,473g) and the median (99g) both walked right past it. Only the percentiles from the Monte Carlo run exposed it.
The fix — smaller squire bonus, a lower win cap, confiscating the stake on a loss, and an injury system — did exactly what you want a balance fix to do:
| Metric | Before | After | Change |
|---|---|---|---|
| Knight gold, P95 | 20,604g | 727g | −96.5% |
| Knight gold, max | 565,216g | 10,058g | −98% |
| "tournament" action share | 92.96% | 62.31% | −31 pts |
| Knight kills the dragon | 47.4% | 48.6% | flat ✓ |
| Full weapon set acquired | 51.4% | 51.8% | flat ✓ |
| Injury rate | 0% | 53.6% | new risk |
It cut the runaway tail by 96%+ while the intended outcomes — knights still kill the dragon, still complete their weapon set — barely moved. That's a surgical fix, and it's only possible because the simulation let me check the things-that-should-stay-the-same at the same time as the thing-I-was-fixing.
Two honesty notes, because I asked the King & Dragon team for them and they matter: those before/after numbers are from the AI simulator, not live players, and the fat-tail run (500 games per variant) is a different experiment from the 10,000-game baseline — don't mix the sample sizes. The ~50% target is the kingdom win rate at a specific strategy mix; the tournament run reports a higher win rate under a different AI configuration. Two separate experiments, not one clean "50% → X" line.
The recipe, if you want to do this yourself
Both games run on the same four moves:
- Make one playthrough a pure, seeded function. No global state, no disk writes, terminates for sure. This is 80% of the work and it pays off everywhere — testing, replays, anti-cheat, and balancing all want the same thing.
- Randomise the inputs and run thousands. Random units, random AI, random seeds. Chimera: 60,000 battles. King & Dragon: 10,000 games.
- Read the distribution, not the average. Plot win rates. Look at P95 and the max, not just the mean. I cannot stress this enough — every real balance bug I've found was hiding in a percentile the average smoothed over.
- Sweep one knob at a time and re-measure. Change Gore's multiplier, nothing else, re-run, plot. Pick the value nearest fair. Then move to the next knob.
And the limit you must keep in mind: you are balancing against your AI, not against humans. The simulation is only as good as the strategies you let the bots play. It's a flashlight, not an oracle. It finds the broken thing fast and cheap, in the dark, before a single player sees it — but live player data is still the final judge.
Play them
Both games are live, and both are running the balance these simulations produced:
- Chimera — breed creatures, watch the genetics, fight with the stats you bred for: chimera.game.marcindudek.dev
- King & Dragon — survive the dragon, run the kingdom's economy, don't get rich enough to get nerfed: king-dragon-game.marcindudek.dev
If you build games, steal the method. Make your playthrough a pure function, simulate it into the ground, and trust the distribution over your gut. Your gut has played twenty games. The computer just played sixty thousand.